

There is a trending term that is floating around in the Artificial Intelligence (AI) field, i.e., “RAG”. So, to satisfy the curiosity, let’s get to know what RAG is. Before that, let us have a brief idea of Generative AI.
What is Generative AI?
Generative AI is an Artificial Intelligence system capable of creating new and original content in the form of text, code, images, audio, and video by learning patterns from large datasets or Large Language Models (LLMs) and analyzing and applying them to produce contextually relevant outputs.
How does it work?
Training: Deep Learning models are trained on large datasets to learn patterns and relationships.
Tuning: Fine-tuning the AI model with LoRA/QLoRA ranking techniques or Reinforcement Learning from Human Feedback (RLHF).
Generation: The AI responds to user queries and prompts by generating text, images, audio, or video based on up-to-date, factual data.
The generative models use “Transformers” to predict the next tokens based on context and produce logical text.
Below is an example of a code snippet that uses transformers to generate the response to a user query:
from transformers import pipeline# Load a pre-trained text generation pipelinegenerator = pipeline("text-generation", model="gpt5")# Generate text based on a promptprompt = "In the future, AI will"result = generator(prompt, max_length=50, num_return_sequences=1)print(result[0]['generated_text'])
Types of models:
Transformers: Text/code generation based on LLMs and uses self-attention for context capture.
Diffusion models: Generate high-quality images/audio by iterative denoising.
GANs and VAEs: Image synthesis, style transfer, data augmentation
Encoder-Decoder: Translation, Summarization, and Multimodal tasks.
Generative AI Applications:
Text-generation (chatbots, summarization, and code generation), Image-generation (Art, medical images), Audio-generation (voice synthesis, music creation), Video-generation (animation, simulation).
Limitations of Generative AI
- Generative AI models are prone to hallucinations and thus are less accurate.
- Generative AI is not real-time. It is limited to its training cut-off, i.e., it does not access updated information until it is retrained.
- It lacks access to the internal and proprietary data (For example, company reports, release notes, etc.).
- It works with Large models and datasets. So it is resource-intensive with respect to compute and storage. So, fine-tuning becomes difficult.
These limitations make the urge to think about an improved methodology and architecture. Here is where “RAG” comes into the picture.
What is RAG?
Retrieval Augmented Generation (RAG) is a technique that adds relevant context to AI, resulting in improved and accurate responses.

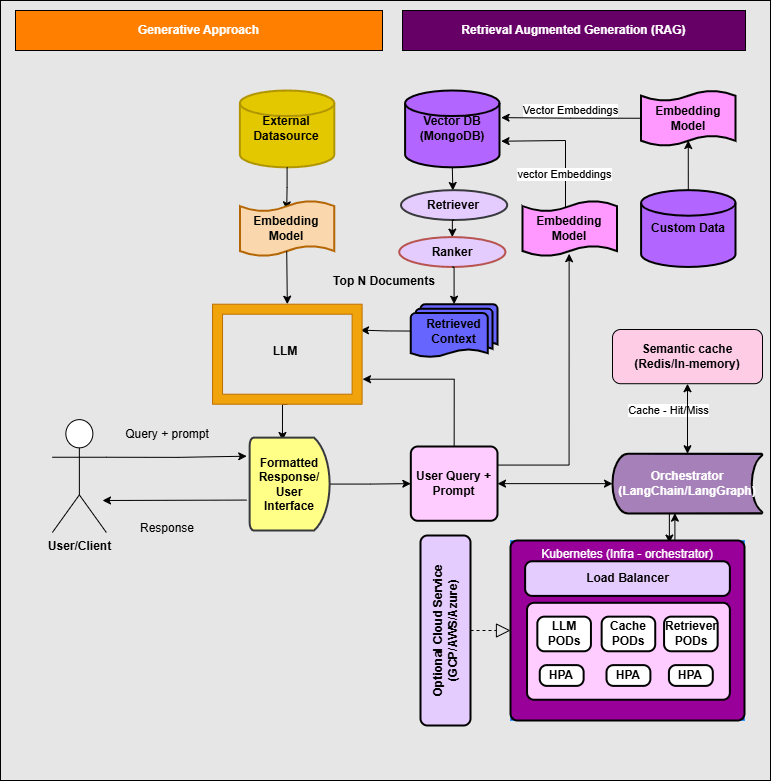
RAG Architecture
Generative AI vs RAG Comparison:
| Aspect | GenAI | RAG |
|---|---|---|
| Accuracy | Prone to hallucinations | Grounded in retrieved sources |
| Knowledge Freshness | Static, limited to training cutoff | Dynamic, can access real-time data |
| Domain Adaptability | Weak with proprietary/internal data | Strong, integrates custom datasets |
| Resource Needs | High (training/fine-tuning) | Lower (retrieval pipeline setup) |
| Creativity | Strong (novel, diverse outputs) | Moderate (depends on retrieved context) |
| Traceability | Limited (no source attribution) | High (answers linked to documents) |
RAG Components
Knowledge Index – An external knowledge source is a foundation for a RAG system. The knowledge source can be any domain-specific custom dataset, documents, databases, APIs, or structured tables.
Document Loader – The document loader standardizes and normalizes the documents from knowledge index data sources such as local files, web pages, cloud storage, or databases. The text splitter extracts the text, splits the text into chunks, and enriches it with metadata for the embedding phase.
Embedding – The text chunks are converted into numerical vectors using embedding models and capturing semantic meaning.
Vector Store – The embeddings are stored in a vector database or vector store. The vector database enables fast similarity searches and retrieves relevant context based on the user’s query.
Retriever – The query encoder converts the user input into a vector representation. The retriever then searches the vector database using semantic similarity or other search techniques to fetch the most relevant chunks of information.
Ranker – The ranker will carry out duplication, relevance ranking, and context enrichment on the vector embeddings. The retrieved and ranked chunks are then combined with the user query to generate a better and more accurate response.
Generator – The generator is the large language model (LLM) that synthesizes the retrieved context and user query to produce a grounded response. The modern RAG systems may use generators for query rewriting, self-evaluation, and corrective re-retrieval.
Output response – Output response is a formatted final response that is sent to the user.
Updator (Optional) – Some RAG systems use an updator to refresh and re-embed the data to ensure the knowledge base remains current and updated. The updator can be equipped with an agentic framework for automated refreshment of knowledge base.
Summary
RAG stands for Retrieval Augmented Generation.
- Retrieval – Find relevant information.
- Augmentation – Add data to AI’s knowledge.
- Generation – Generate a better and more accurate response.
The purpose of RAG is to add relevant context to AI and generate an accurate response.
